
I am Wenxuan Song (宋文轩 in Chinese), a first-year Ph.D. student at the ROAS Thrust at the Hong Kong University of Science and Technology (HKUST), Guangzhou campus, advised by Haoang Li. I received my Bachelor’s degree in robotics at Harbin Institute of Technology (HIT), Weihai Campus, advised by Minghang Zhao and Bo Huang. I was a visiting student at MiLab, Westlake University, supervised by Donglin Wang. I keep a close connection with Pengxiang Ding and Han Zhao from then on, who have been teaching me a lot. I also spent time at Monash University, supervised by Zongyuan Ge and Xuelian Cheng.
Goal: Pushing the boundaries of the world through robotics.
Focus: Building dexterous and generalizable robotic systems through Vision-Language-Action models and world models.
Email: songwenxuan0115 [AT] gmail.com
🔥 Projects
-
Embodied-AI-Paper-TopConf
: We collect published papers in the field of embodied intelligence.
-
LLaVA-VLA
: We propose a simple yet effective Vision-Language-Action model built upon the popular open-source VLM LLaVA.
-
OpenHelix
: We propose an open-source dual-system VLA model for robotic manipulation.
📝 Selected Publications
- For full publications, please refer to my Google Scholar.
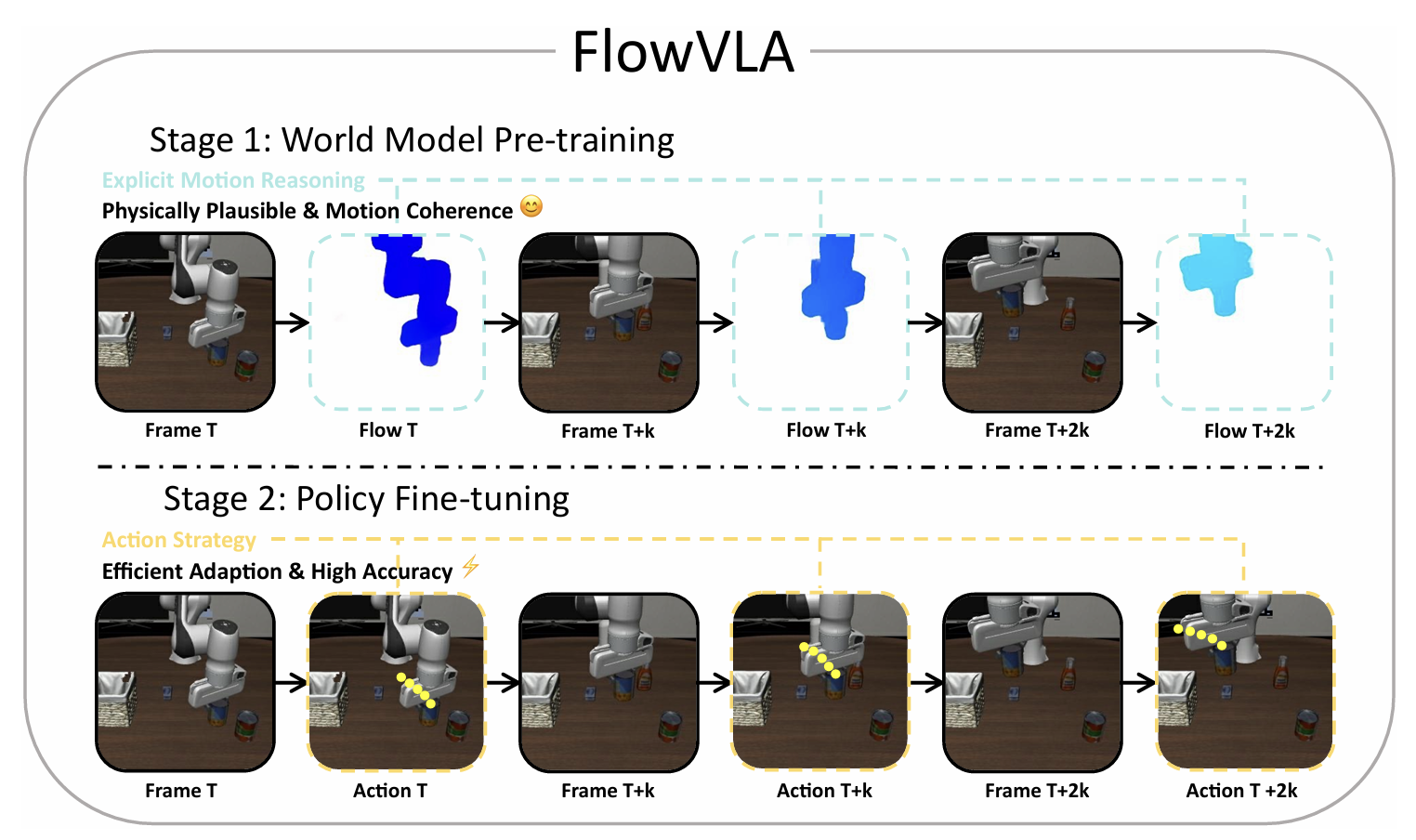
FlowVLA: Thinking in Motion with a Visual Chain of Thought
Zhide Zhong, Haodong Yan, Junfeng Li, Xiangchen Liu, Xin Gong, Wenxuan Song, Jiayi Chen, Haoang Li
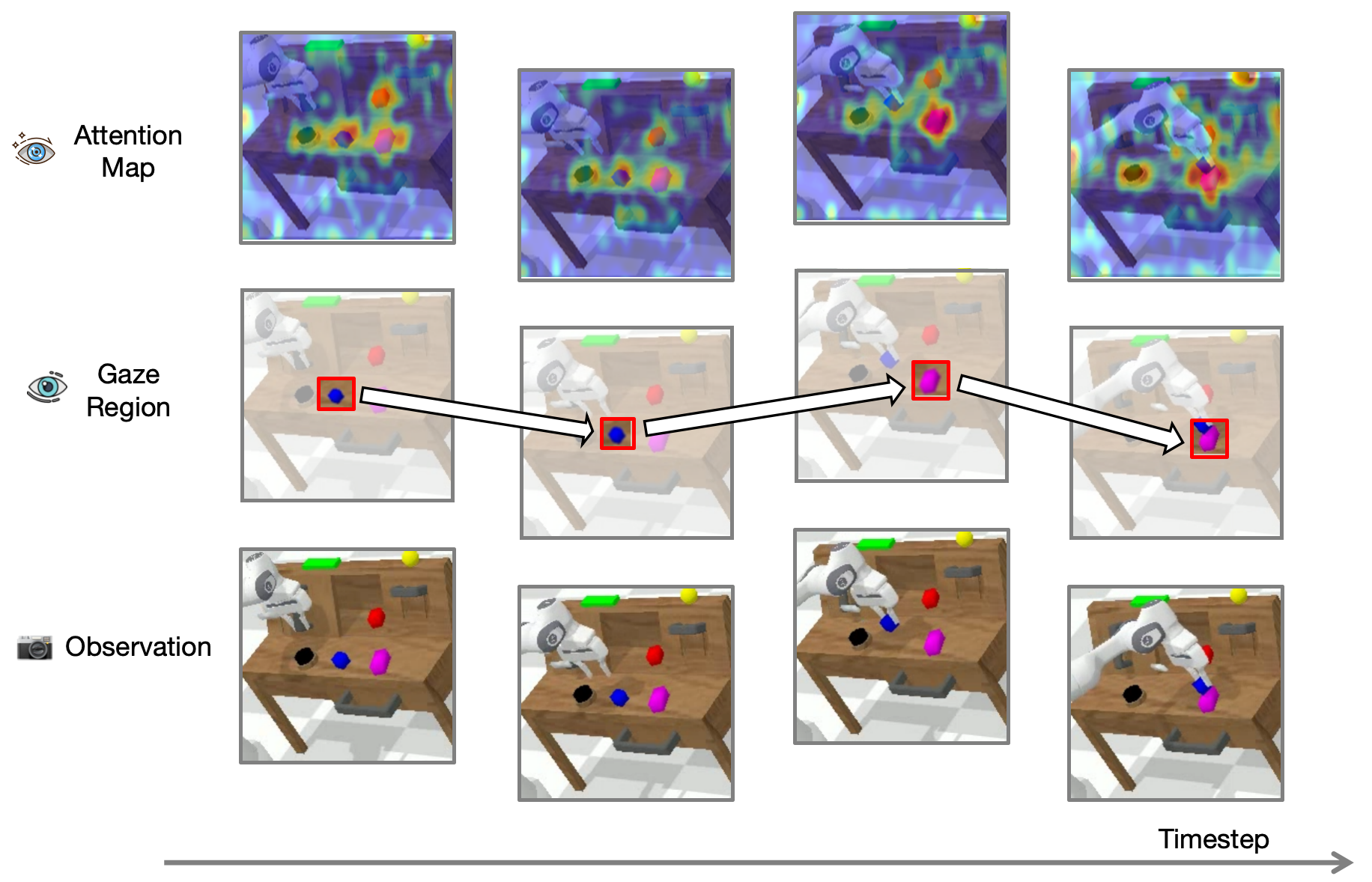
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, Haoang Li
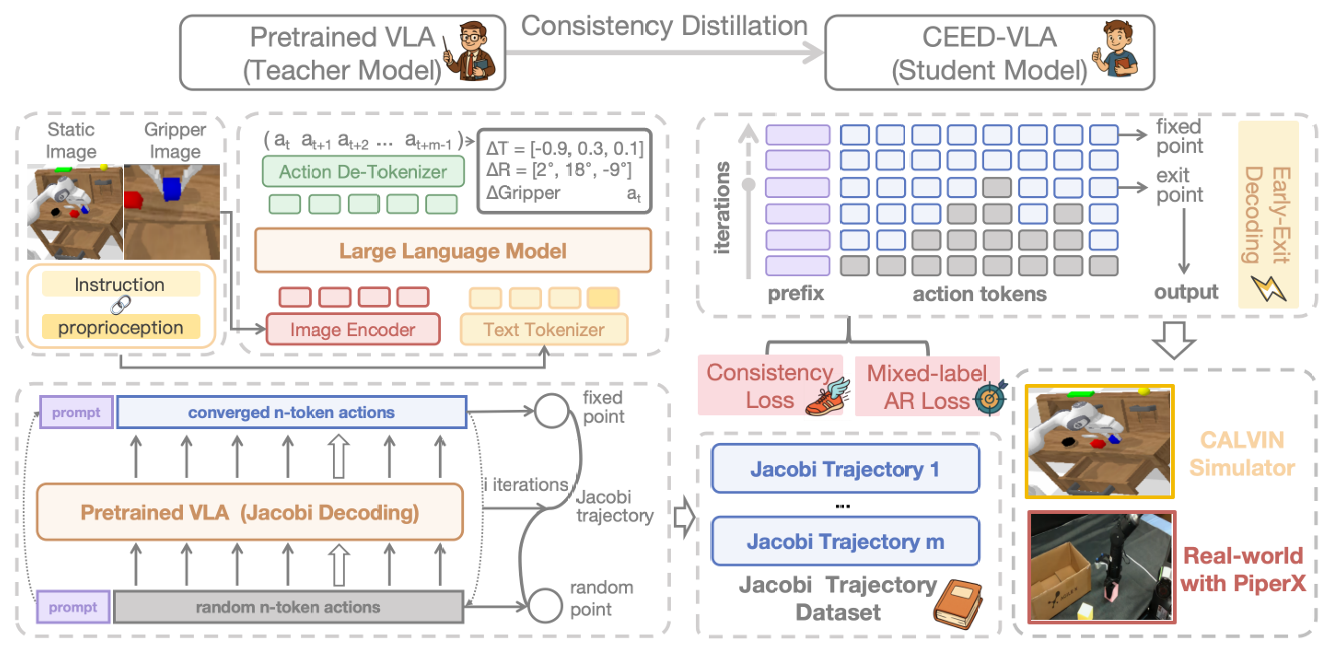
CEED-VLA: Consistency Vision-Language-Action Model with Early-Exit Decoding
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Yuxin Huang, Han Zhao, Donglin Wang, Haoang Li
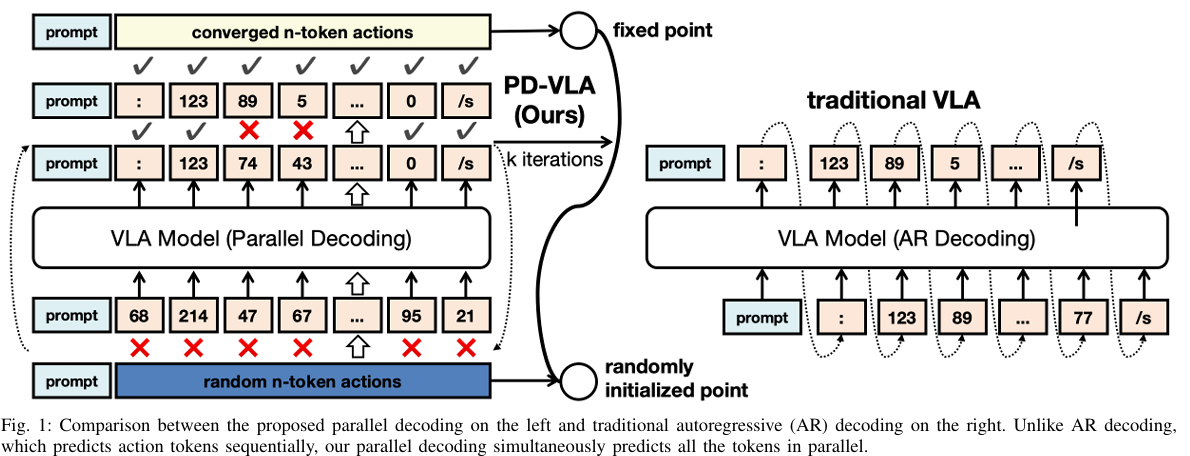
Accelerating Vision-Language-Action Model Integrated with Action Chunking via Parallel Decoding
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Han Zhao, Wei Zhao,Zhide Zhong, Zongyuan Ge, Jun Ma, Haoang Li
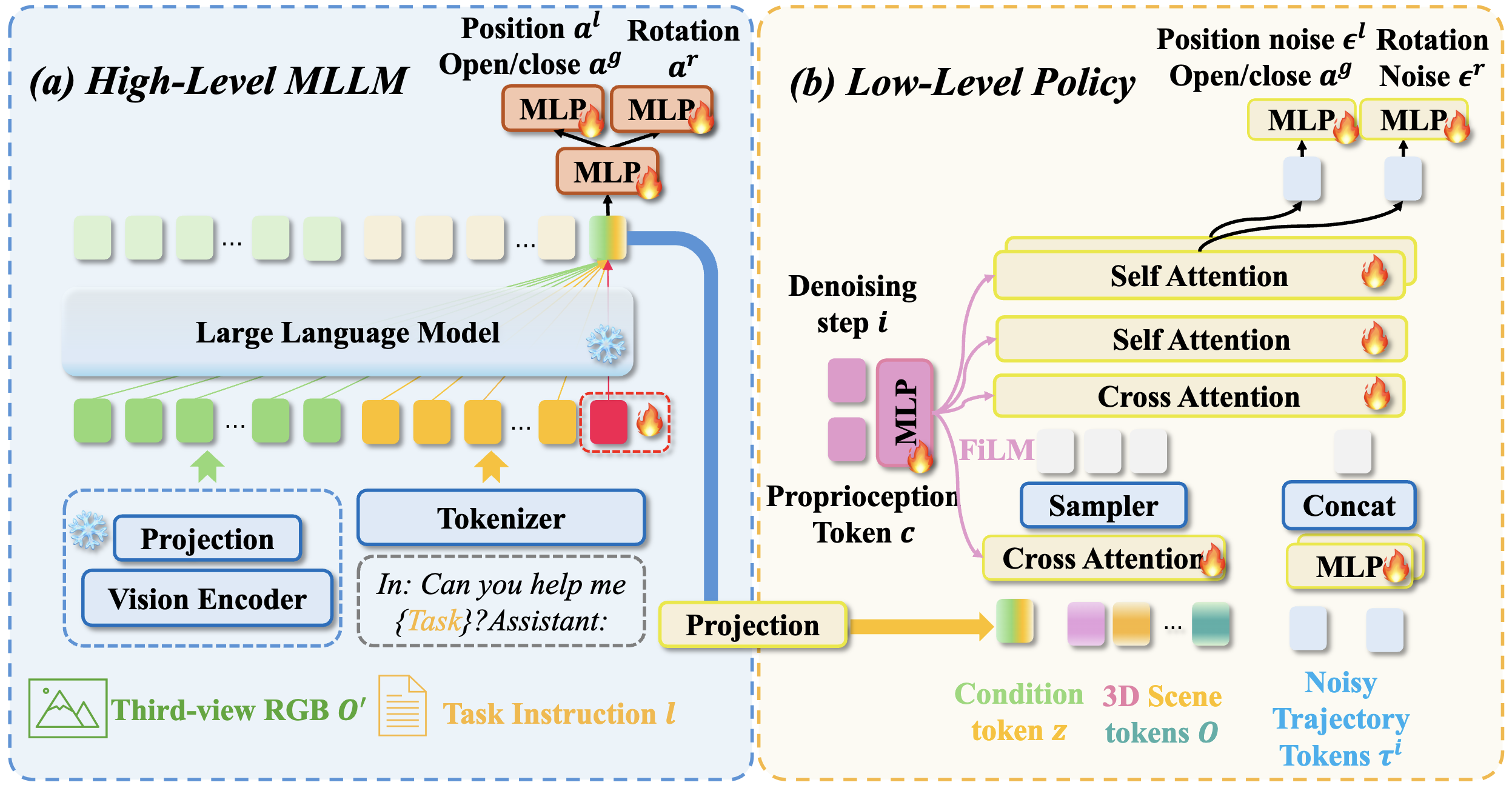
Can Cui, Pengxiang Ding, Wenxuan Song, Shuanghao Bai, Xinyang Tong, Zirui Ge, Runze Suo,
Wanqi Zhou, Yang Liu, Bofang Jia, Han Zhao, Siteng Huang, Donglin Wang
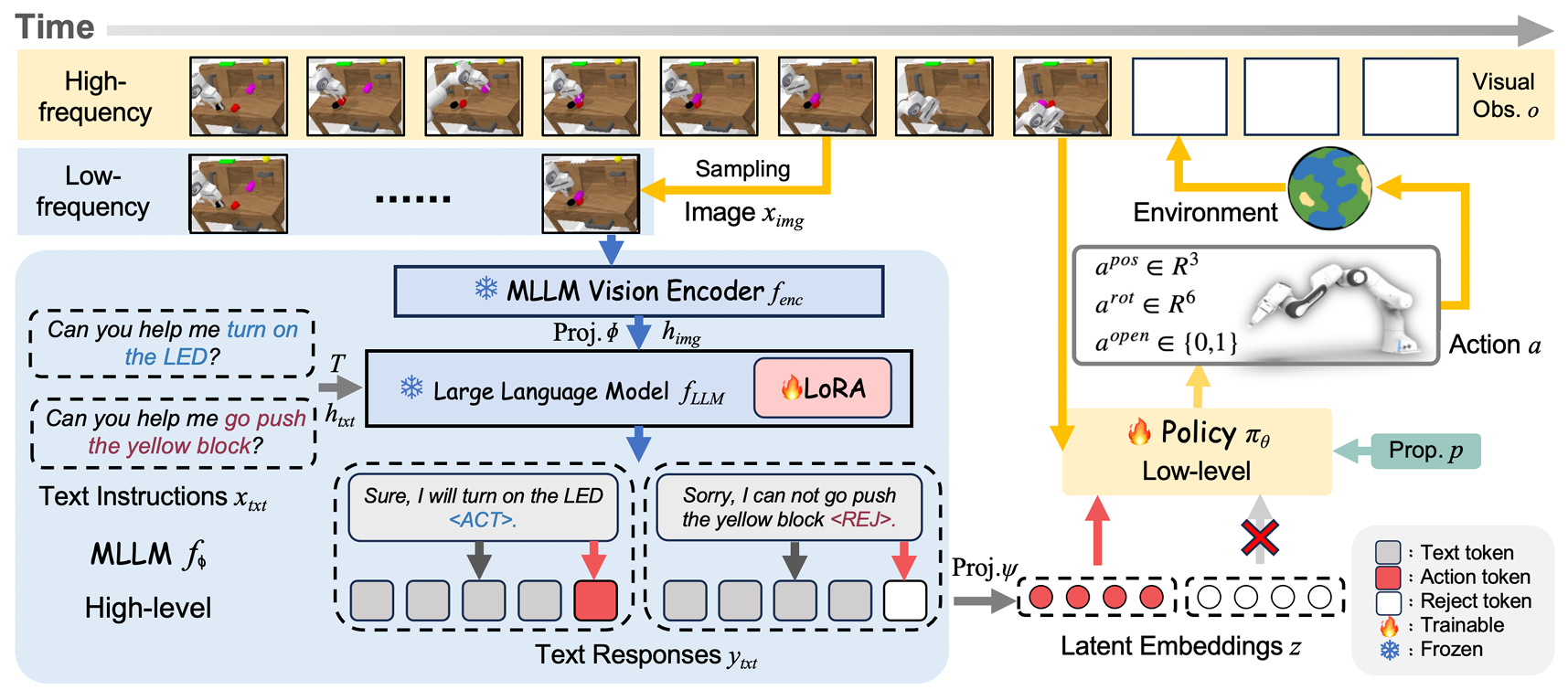
RationalVLA: A Rational Vision-Language-Action Model with Dual System
Wenxuan Song, Jiayi Chen, Wenxue Li, Xu He, Han Zhao, Can Cui, Pengxiang Ding, Shiyan Su, Feilong Tang, Donglin Wang, Xuelian Cheng, Zongyuan Ge, Xinhu Zheng, Zhe Liu, Hesheng Wang, Haoang Li
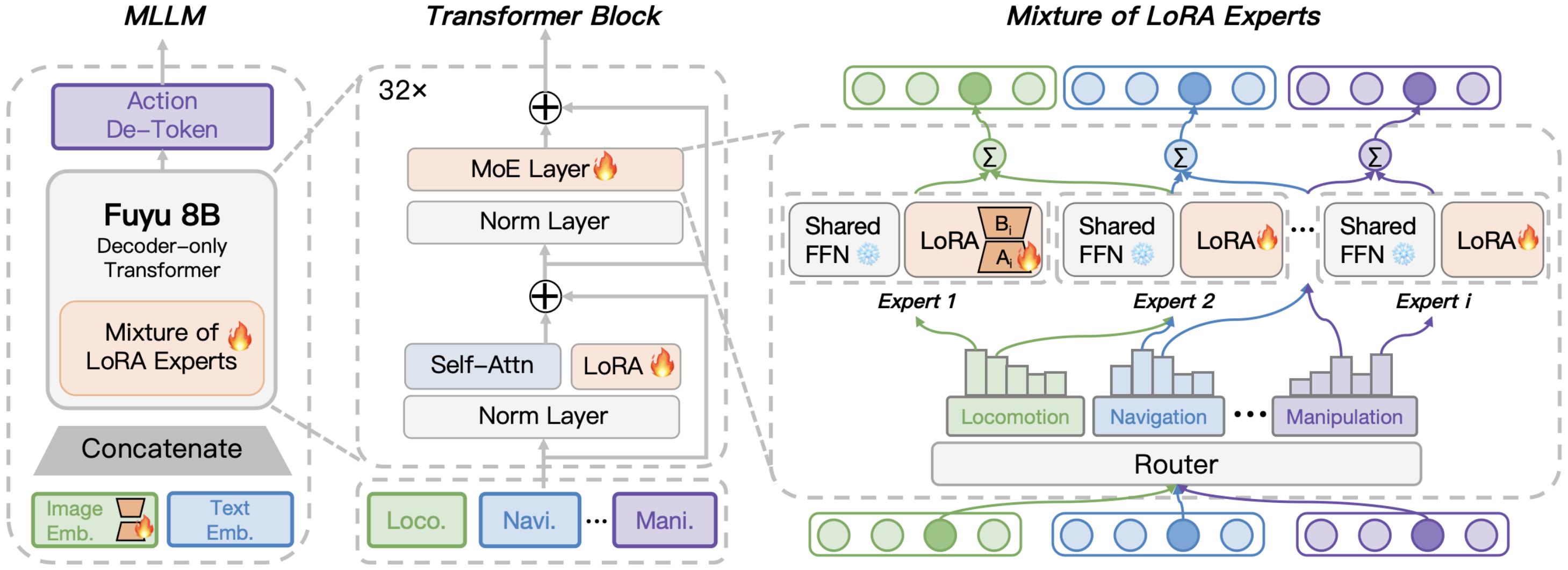
MoRE: Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models
Han Zhao, Wenxuan Song, Donglin Wang, Xinyang Tong, Pengxiang Ding, Xuelian Cheng, Zongyuan Ge
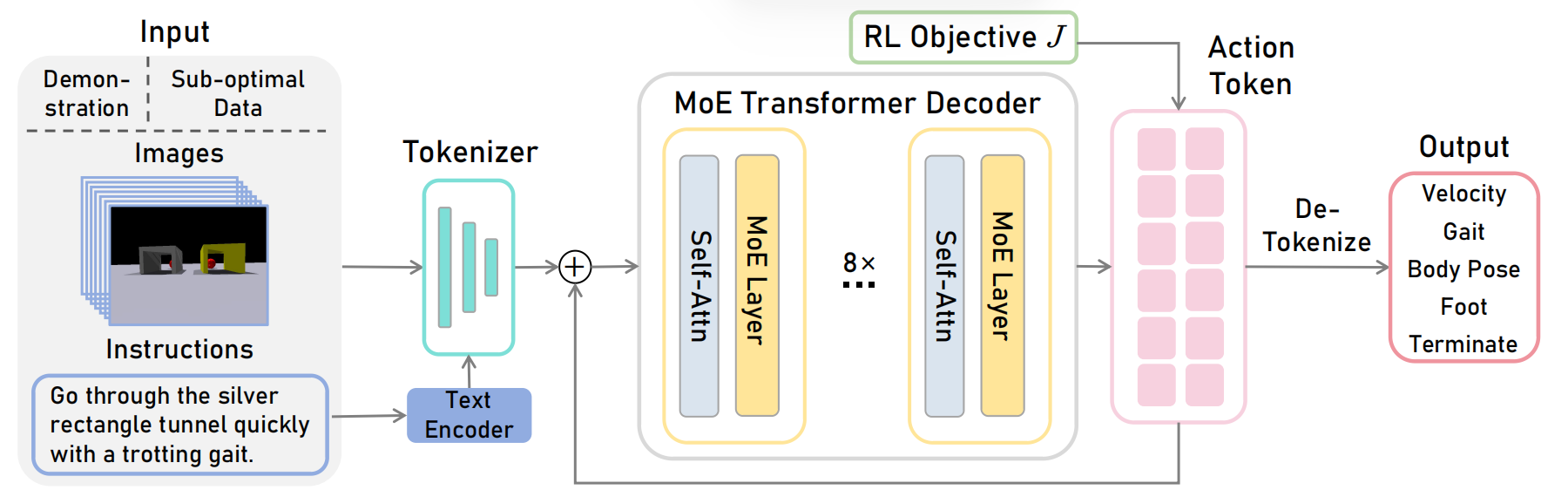
GeRM: A Generalist Robotic Model with Mixture-of-experts for Quadruped Robots
Wenxuan Song, Han Zhao, Pengxiang Ding, Can Cui, Shangke Lyu, Yaning Fan, Donglin Wang
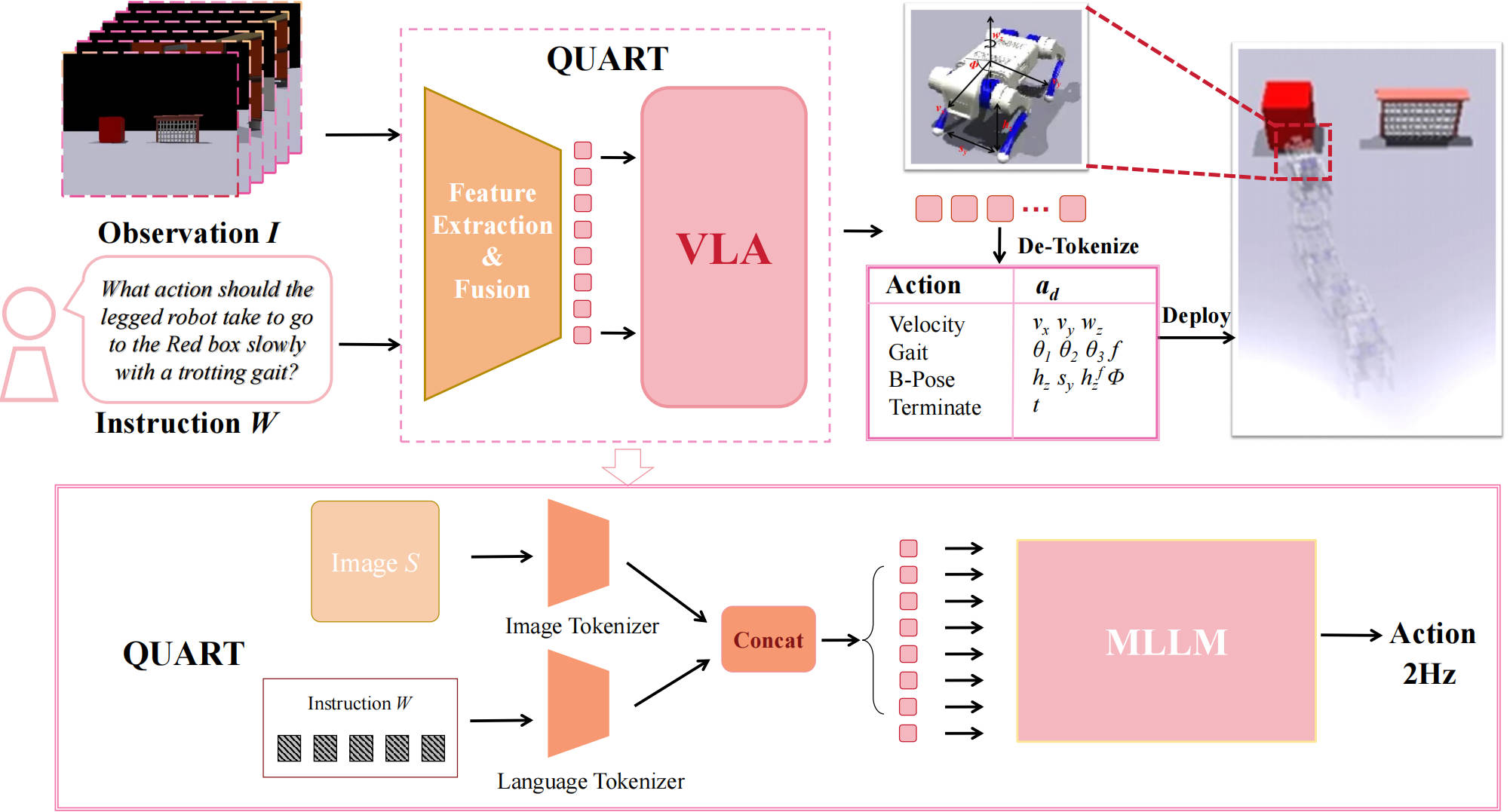
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
Pengxiang Ding, Han Zhao, Wenxuan Song, Wenjie Zhang, Min Zhang, Siteng Huang, Ningxi Yang, Donglin Wang