
I am Wenxuan Song (宋文轩), a second-year Ph.D. student in the ROAS Thrust at the Hong Kong University of Science and Technology (Guangzhou), advised by Haoang Li. My research focuses on foundation models for embodied intelligence. I have been conducting research in embodied intelligence and robot learning, with publications in top-tier venues including ICLR, ECCV, CVPR, and the IEEE Transactions series. So far, I have published 20 papers, including 10 first-author or co-first-author papers.
My work ReconVLA: Reconstructive Vision–Language–Action Model as Effective Robot Perceiver received the AAAI 2026 Best Paper Award. To the best of my knowledge, it is the first embodied AI work to receive a best paper award at a top-tier machine learning conference. This work also initiated the research direction of robot visual representation alignment. Follow-up work in this line, Spatial Forcing, was adopted in the runner-up solution of the IROS 2025 Agibot World Challenge and was later accepted to ICLR 2026. I was also honored as an ICML 2026 Gold Reviewer.
Beyond research, I am a co-founder of the open-source organization OpenHelix Team, where the repositories I have substantially led or contributed to have collectively gained over 4,000 GitHub stars. My work has been adopted in industrial models by companies such as Robbyant and Xiaomi, and has been widely recognized both in academia and industry. Related work has also been featured by MIT Technology Review.
Previously, I received my Bachelor’s degree in Robotics at Harbin Institute of Technology (HIT), Weihai Campus, advised by Minghang Zhao and Bo Huang. I was also a visiting student at MiLab, Westlake University, supervised by Donglin Wang, and I have maintained close connections with Pengxiang Ding and Han Zhao, from whom I have learned a great deal. I also spent time at Monash University, supervised by Zongyuan Ge and Xuelian Cheng.
Goal: Advancing toward robotics’ GPT-3.5 moment.
Focus: Building dexterous and generalizable robotic systems through Vision-Language-Action models and world models.
Email: songwenxuan0115 [AT] gmail.com
🏆 Honors
- Best Paper Award, The 40th Annual AAAI Conference on Artificial Intelligence (AAAI-26), (5/30948), 2026
- Champion, ICRA-26 WBCD Competition (Deformable Track), 2026
- Champion, ICRA-26 WBCD Competition (Logistic Picking Track), 2026
- Innovibe Rising Star Award, Beijing Academy of Artificial Intelligence (BAAI), (20 selected annually), 2026
- Next-20 Award, Embodied AI 100 in China, (20 selected annually), 2026
- Golden Reviewer, International Conference of Machine Learning (ICML-26), 2026
🔥 Projects
- Embodied-AI-Paper-TopConf
: We collect published papers in the field of embodied intelligence.
- VLA-Adapter
: We propose a simple but effective VLA baseline.
- OpenHelix
: We propose an open-source dual-system VLA model for robotic manipulation.
📝 Selected Publications
- For full publications, please refer to my Google Scholar.
Fast-dVLA: Accelerating Discrete Diffusion VLA to Real-Time Performance
Wenxuan Song, Jiayi Chen, Shuai Chen, Jingbo Wang, Pengxiang Ding, Han Zhao, Yikai Qin, Xinhu Zheng, Donglin Wang, Yan Wang, Haoang Li
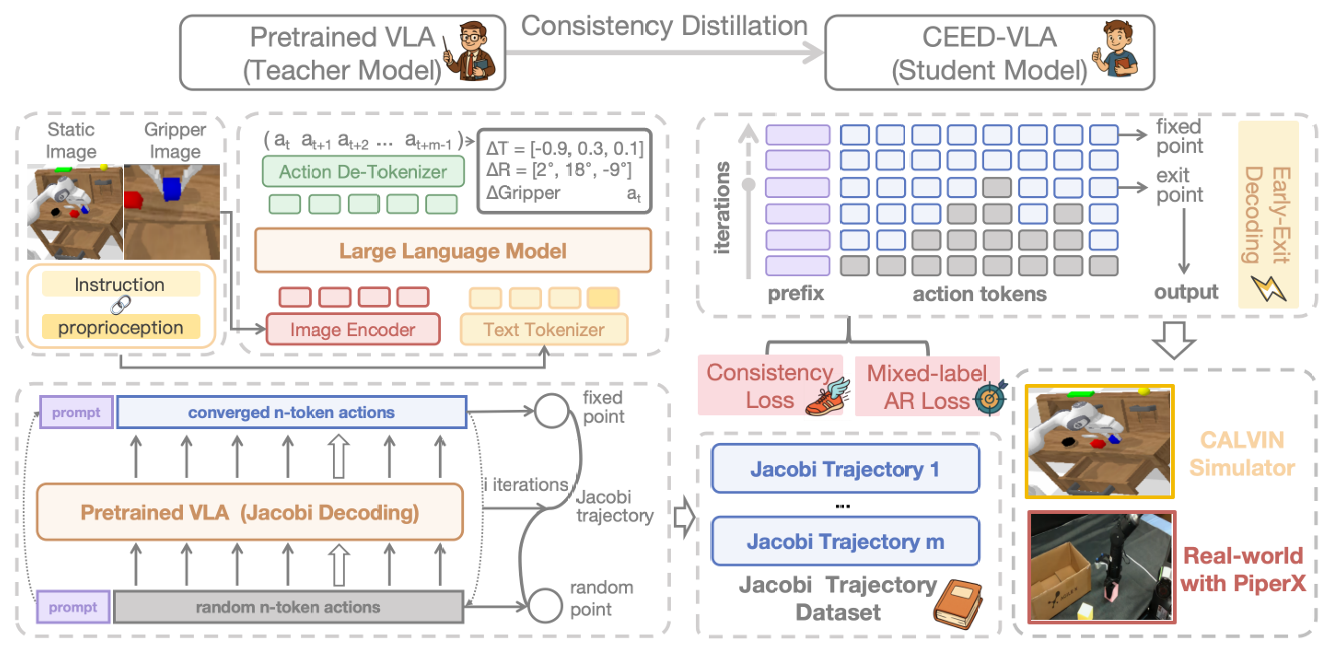
CEED-VLA: Consistency Vision-Language-Action Model with Early-Exit Decoding
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Yuxin Huang, Han Zhao, Yinchuan Li, Ying-Cong Chen, Donglin Wang, Haoang Li
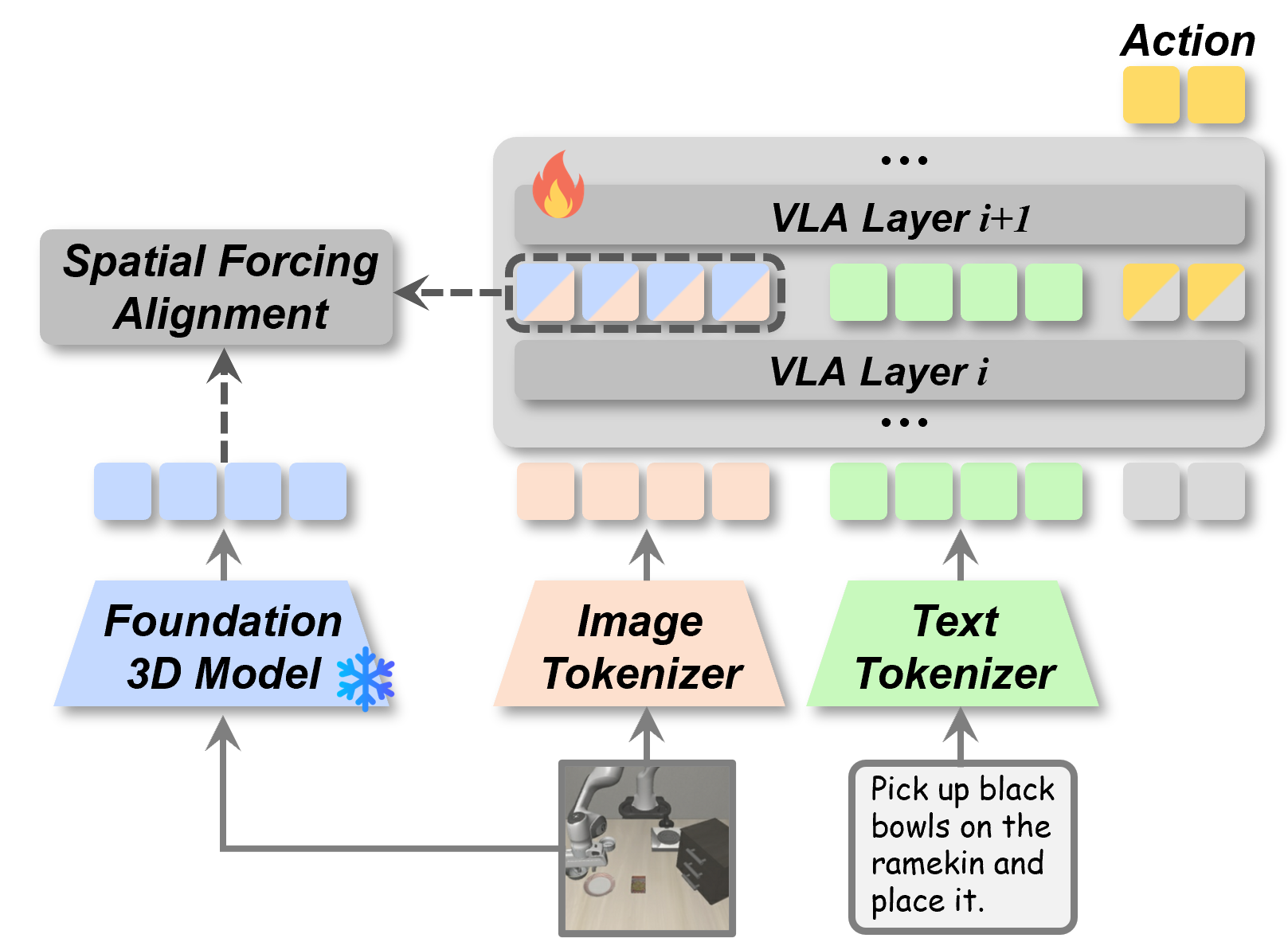
Spatial Forcing: Implicit Spatial Representation Alignment for Vision–Language–Action Models
Fuhao Li*, Wenxuan Song*, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, Haoang Li
* denotes equal contribution, ‡ denotes project lead
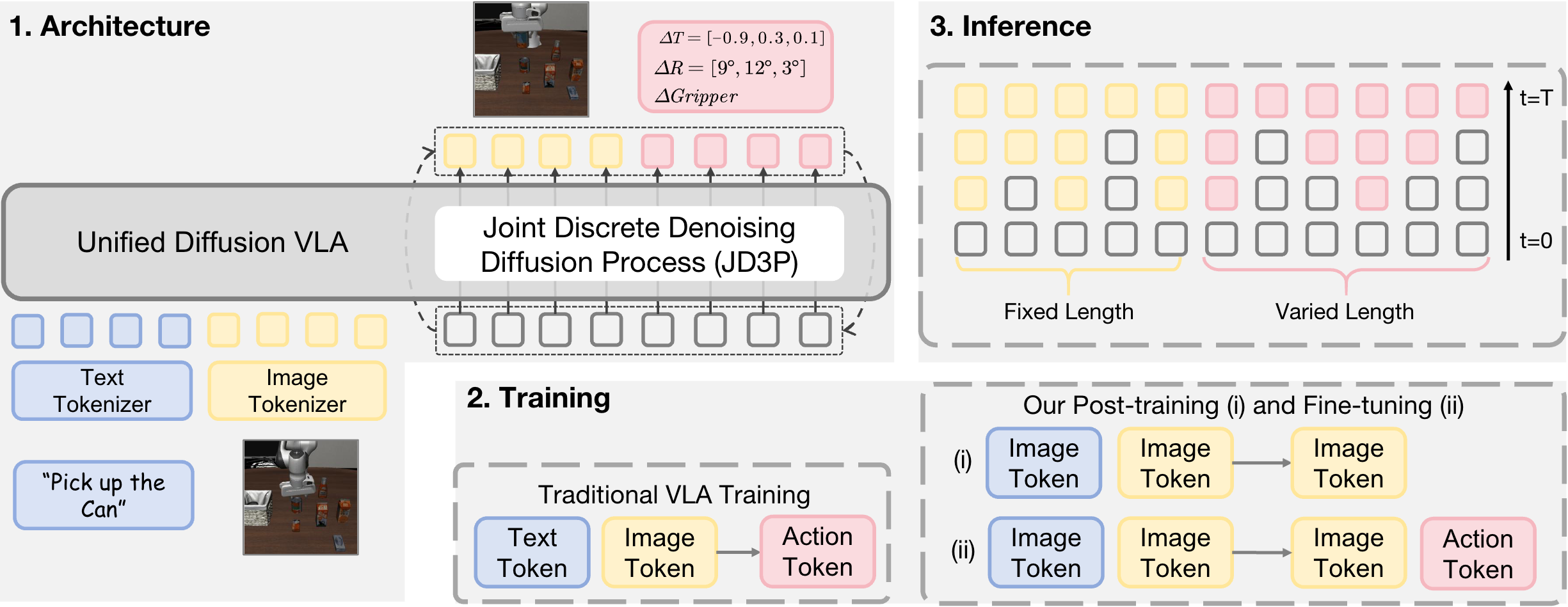
Unified Diffusion VLA: Vision–Language–Action Model via Joint Discrete Denoising Diffusion Process
Jiayi Chen, Wenxuan Song, Pengxiang Ding, Ziyang Zhou, Han Zhao, Feilong Tang, Donglin Wang, Haoang Li
* denotes equal contribution, ‡ denotes project lead
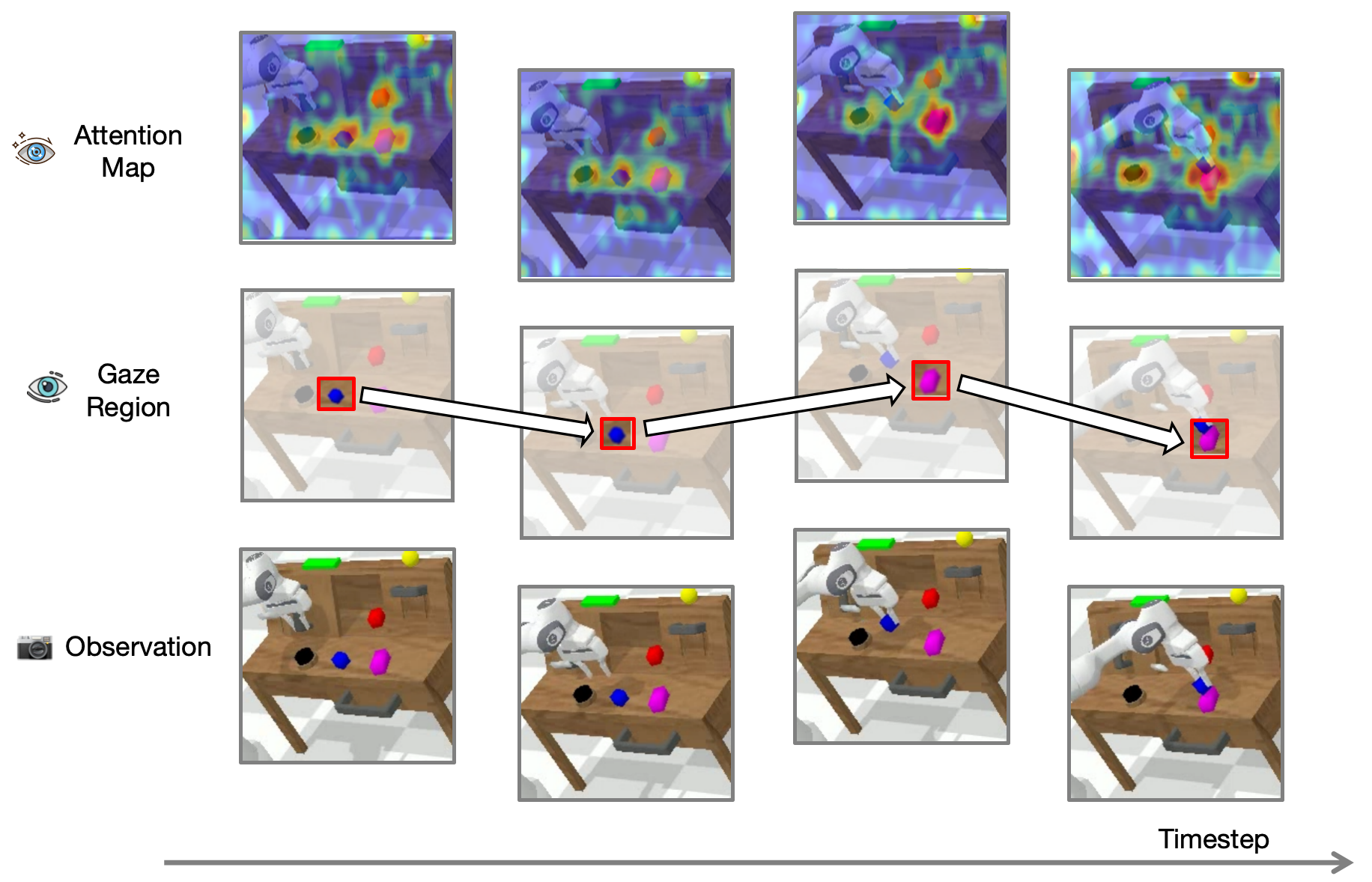
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, Haoang Li
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision–Language–Action Models
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, Siteng Huang, Yifan Tang, Wenhui Wang, Ru Zhang, Jianyi Liu, Donglin Wang
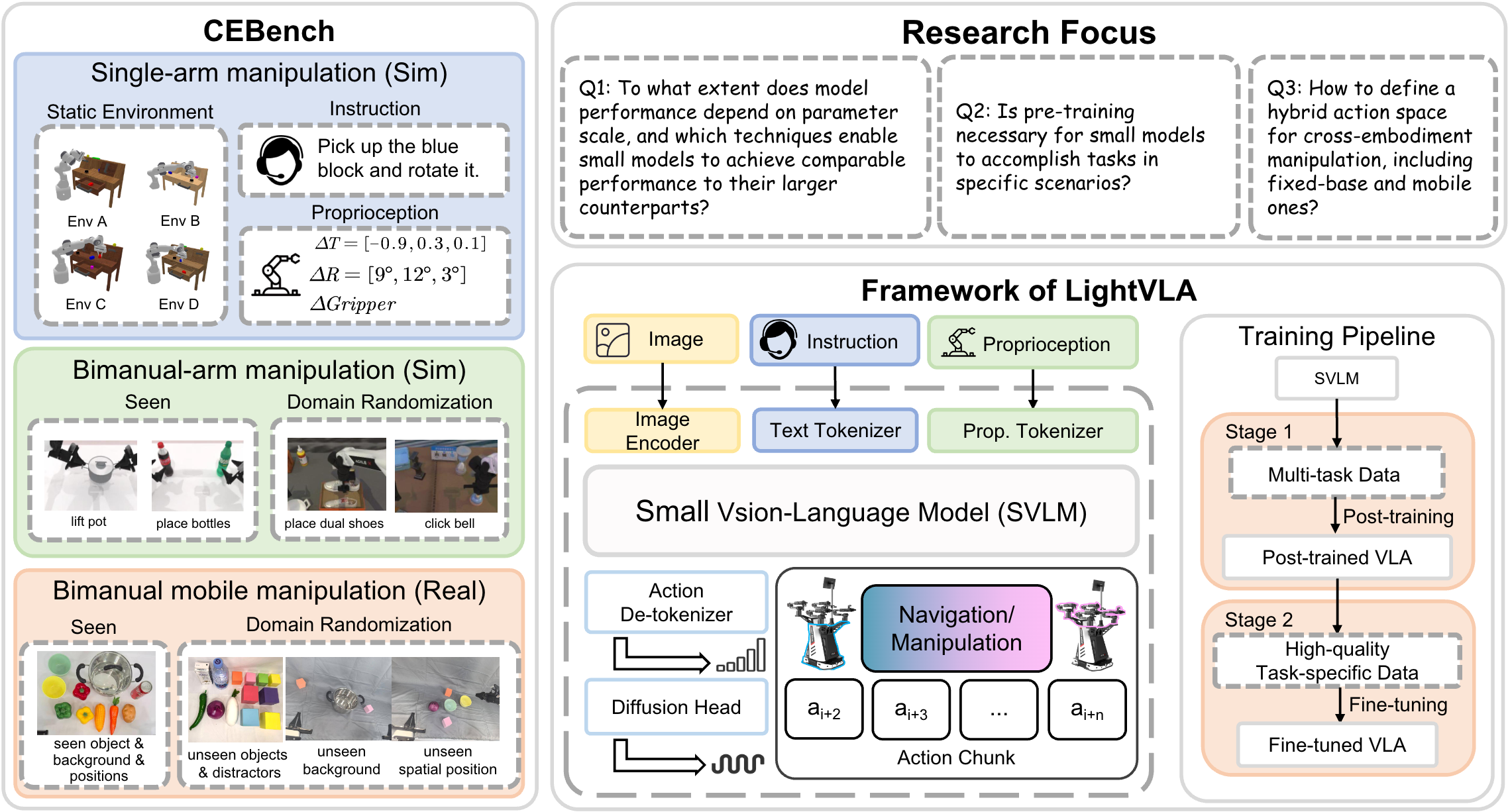
Wenxuan Song, Jiayi Chen, Xiaoquan Sun, Huashuo Lei, Yikai Qin, Wei Zhao, Pengxiang Ding, Han Zhao, Tongxin Wang, Pengxu Hou, Zhide Zhong, Haodong Yan, Donglin Wang, Jun Ma, Haoang Li
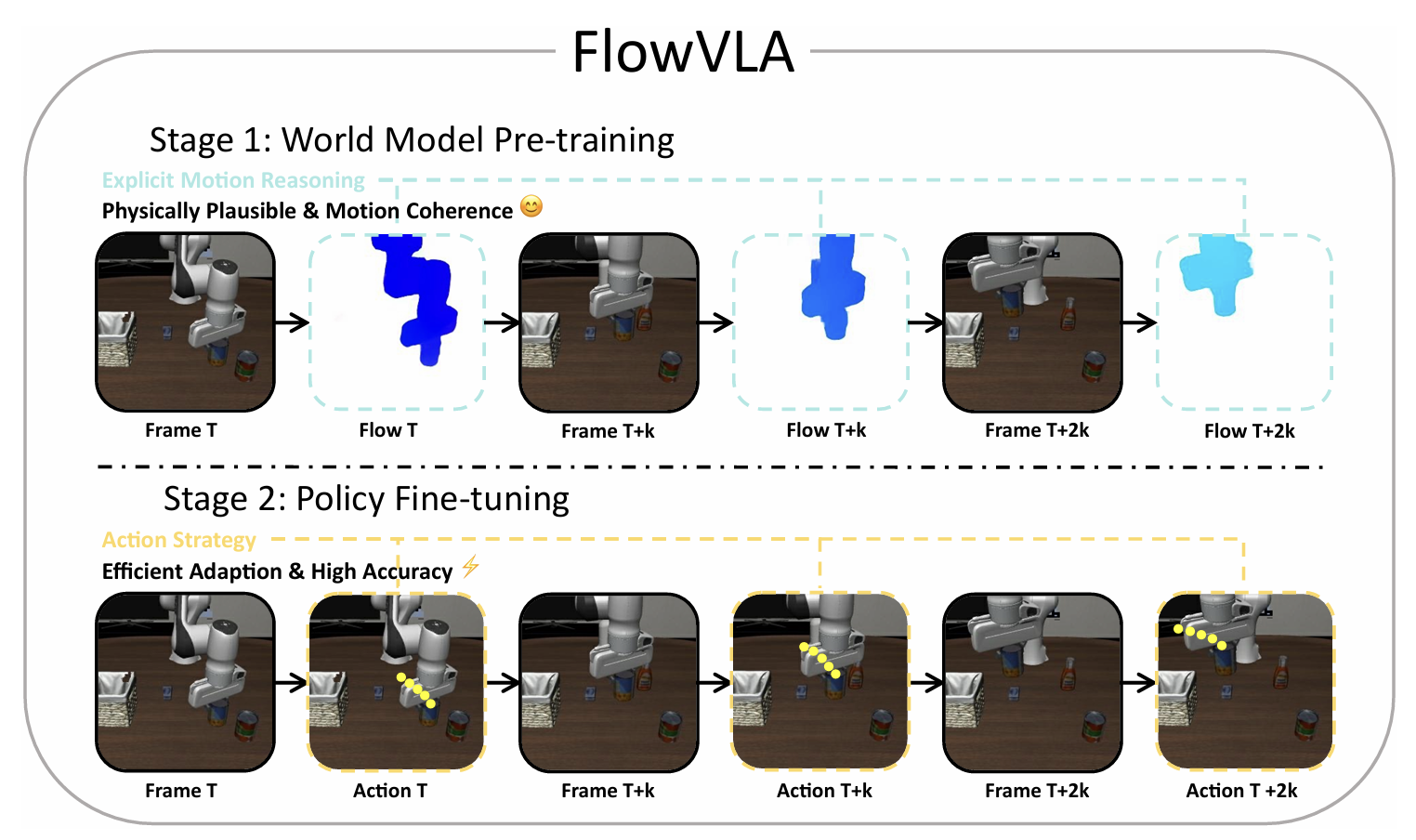
FlowVLA: Thinking in Motion with a Visual Chain of Thought
Zhide Zhong, Haodong Yan, Junfeng Li, Xiangchen Liu, Xin Gong, Wenxuan Song, Jiayi Chen, Haoang Li
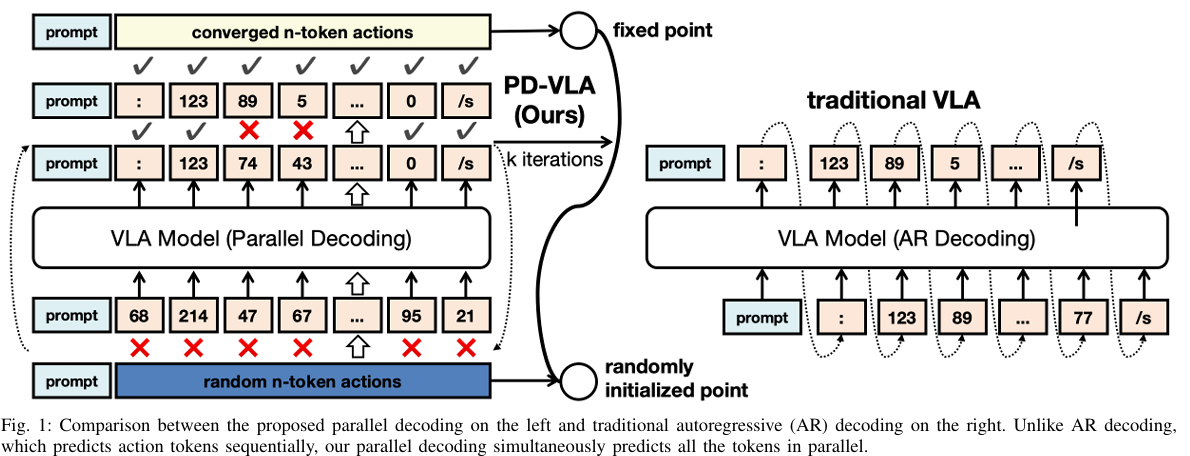
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Han Zhao, Wei Zhao,Zhide Zhong, Zongyuan Ge, Jun Ma, Haoang Li
Can Cui, Pengxiang Ding, Wenxuan Song, Shuanghao Bai, Xinyang Tong, Zirui Ge, Runze Suo,
Wanqi Zhou, Yang Liu, Bofang Jia, Han Zhao, Siteng Huang, Donglin Wang
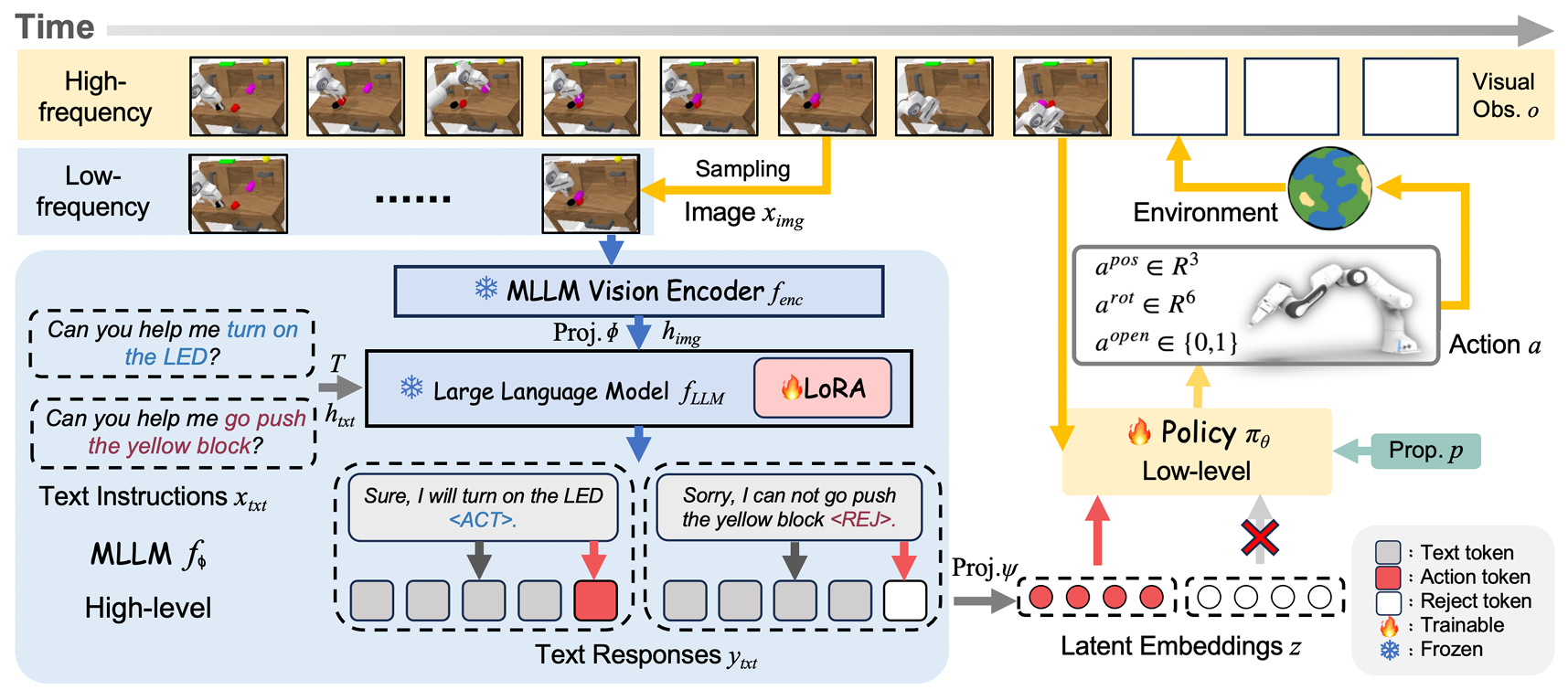
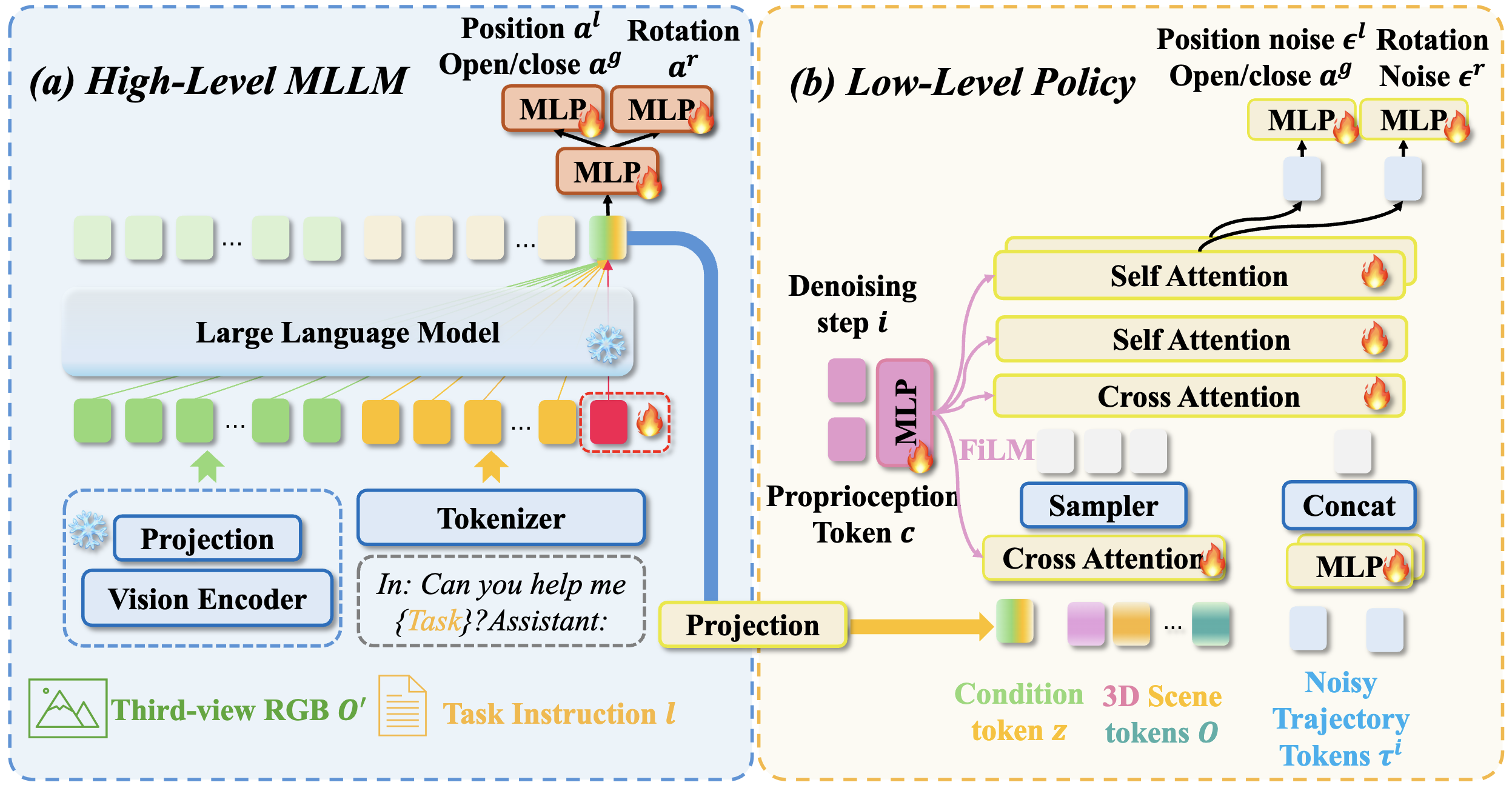
RationalVLA: A Rational Vision-Language-Action Model with Dual System
Wenxuan Song, Jiayi Chen, Wenxue Li, Xu He, Han Zhao, Can Cui, Pengxiang Ding, Shiyan Su, Feilong Tang, Donglin Wang, Xuelian Cheng, Zongyuan Ge, Xinhu Zheng, Zhe Liu, Hesheng Wang, Haoang Li
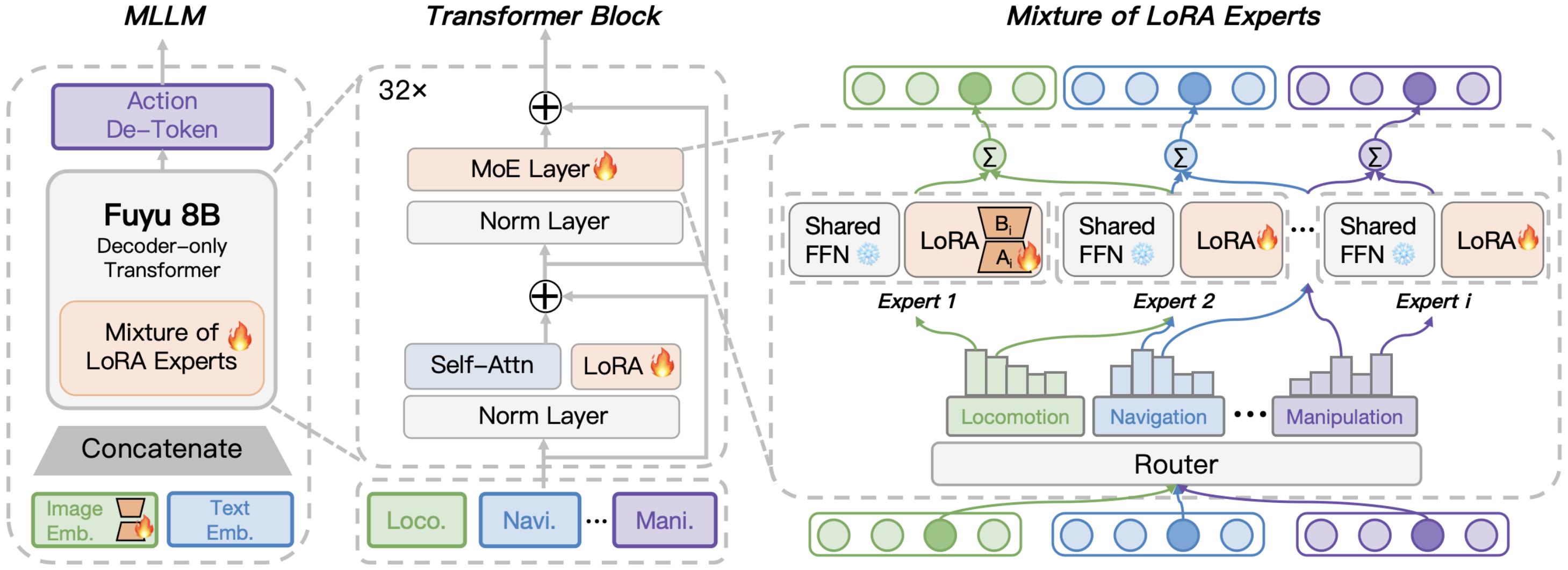
MoRE: Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models
Han Zhao, Wenxuan Song, Donglin Wang, Xinyang Tong, Pengxiang Ding, Xuelian Cheng, Zongyuan Ge
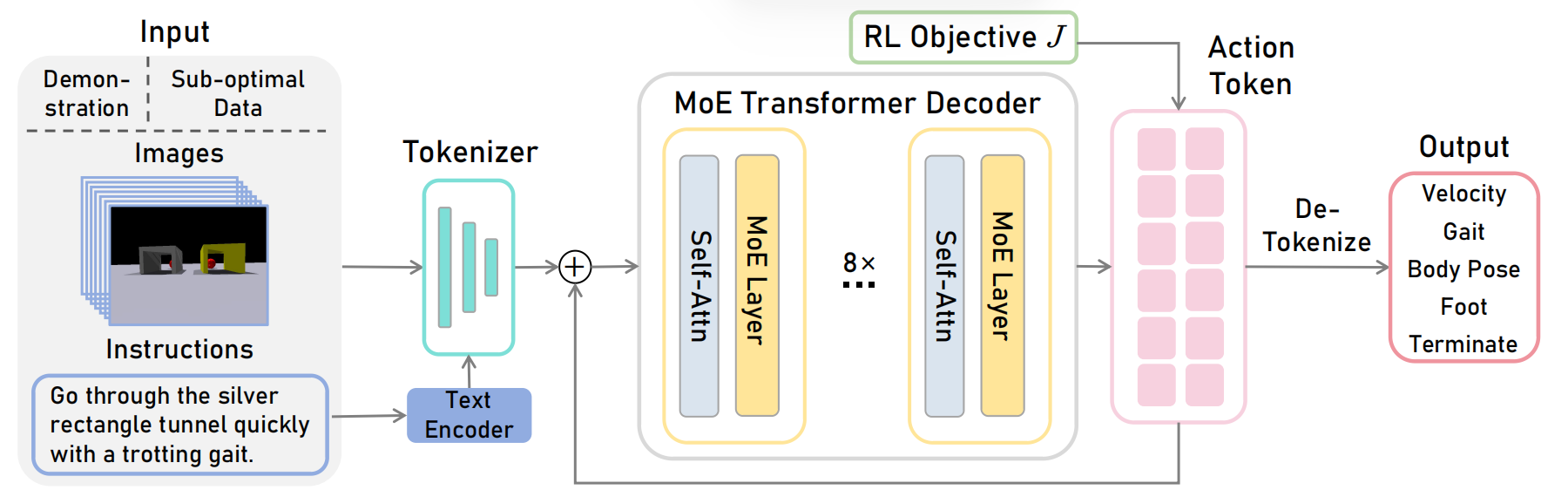
GeRM: A Generalist Robotic Model with Mixture-of-experts for Quadruped Robots
Wenxuan Song, Han Zhao, Pengxiang Ding, Can Cui, Shangke Lyu, Yaning Fan, Donglin Wang
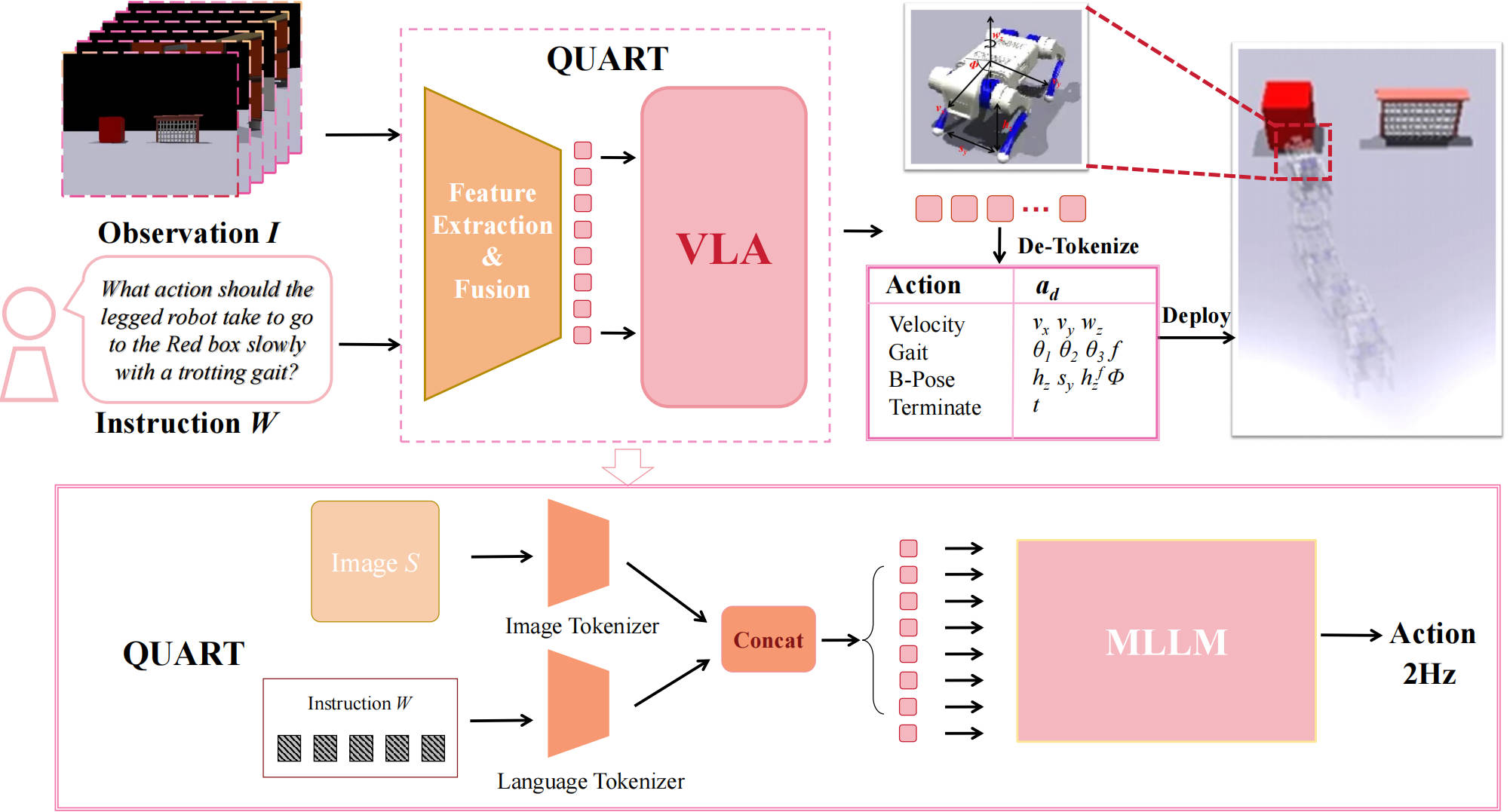
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
Pengxiang Ding, Han Zhao, Wenxuan Song, Wenjie Zhang, Min Zhang, Siteng Huang, Ningxi Yang, Donglin Wang
💬 Invited Talks
- Invited talks at the Pine Lab, Nanyang Technological University (group led by Prof. Ziwei Wang),
AIR, Tsinghua University (group led by Prof. Yan Wang),
Auto Lab, Shanghai Jiao Tong University (group led by Prof. Zhipeng Zhang),
Zhejiang University (group led by Prof. Chunhua Shen),
The Hong Kong University of Science and Technology (Guangzhou) (group led by Prof. Jia Li),
and the BAAI Innovation Center, among others.